Example of Sqlite Database in Android
Introduction
Android default
Database engine is Lite.
SQLite is a lightweight transactional
database engine that occupies a small amount of disk storage and memory, so it's a perfect choice for creating
databases on many mobile operating systems such as
Android, iOS.
Things to consider when dealing with
SQLite:
- Data type integrity is not maintained in SQLite, you can put a value of a certain data type in a column of another datatype (put
string in an integer and vice versa).
- Referential integrity is not maintained in SQLite, there is no
FOREIGN KEY constraints or JOIN statements.
- SQLite Full Unicode support is optional and not installed by default.
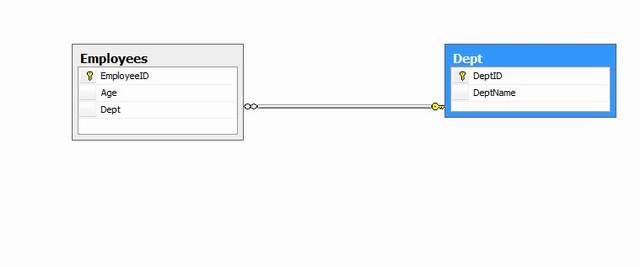
In this tutorial, we will create a simple
database application to store employees data. the DB has:
Tables
EmployeesDept
Views
ViewEmps: to display employees and their relative departments.
Creating SQLite Database
By default,
SQLite on
Android does not have a management interface or an application to create and manage
databases from, so we're going to create the
database ourselves by code. First, we will create a class that handles all the operations required to deal with the
database such as creating the
database, creating tables, inserting and deleting records and so on. The first step is to create a class that inherits from
SQLiteOpenHelper class. This class provides two methods to override to deal with the
database:
onCreate(SQLiteDatabase db): invoked when the database is created, this is where we can create tables and columns to them, create views or triggers. onUpgrade(SQLiteDatabse db, int oldVersion, int newVersion): invoked when we make a modification to the database such as altering, dropping , creating new tables.
Our class will have the following members:
public class DatabaseHelper extends SQLiteOpenHelper {
static final String dbName="demoDB";
static final String employeeTable="Employees";
static final String colID="EmployeeID";
static final String colName="EmployeeName";
static final String colAge="Age";
static final String colDept="Dept";
static final String deptTable="Dept";
static final String colDeptID="DeptID";
static final String colDeptName="DeptName";
static final String viewEmps="ViewEmps";The Constructor
public DatabaseHelper(Context context) {
super(context, dbName, null,33);
}The constructor of the super class has the following parameters:
Context con: The context attached to the databasedataBaseName: The name of the databaseCursorFactory: Sometimes, we may use a class that extends the Cursor class to implement some extra validations or operations on the queries run on the database. In this case, we pass an instance of CursorFactory to return a reference to our derived class to be used instead of the default cursor. In this example, we are going to use the standard Cursor Interface to retrieve results, so the CursorFactory parameter is going to be null. Version: the version of the schema of the database. The constructor creates a new blank database with the specified name and version.
Creating the Database
The first superclass method to override is
onCreate(SQLiteDatabase db):
public void onCreate(SQLiteDatabase db) {
db.execSQL("CREATE TABLE "+deptTable+" ("+colDeptID+ " INTEGER PRIMARY KEY , "+
colDeptName+ " TEXT)");
db.execSQL("CREATE TABLE "+employeeTable+"
("+colID+" INTEGER PRIMARY KEY AUTOINCREMENT, "+
colName+" TEXT, "+colAge+" Integer, "+colDept+"
INTEGER NOT NULL ,FOREIGN KEY ("+colDept+") REFERENCES
"+deptTable+" ("+colDeptID+"));");
db.execSQL("CREATE TRIGGER fk_empdept_deptid " +
" BEFORE INSERT "+
" ON "+employeeTable+
" FOR EACH ROW BEGIN"+
" SELECT CASE WHEN ((SELECT "+colDeptID+" FROM "+deptTable+"
WHERE "+colDeptID+"=new."+colDept+" ) IS NULL)"+
" THEN RAISE (ABORT,'Foreign Key Violation') END;"+
" END;");
db.execSQL("CREATE VIEW "+viewEmps+
" AS SELECT "+employeeTable+"."+colID+" AS _id,"+
" "+employeeTable+"."+colName+","+
" "+employeeTable+"."+colAge+","+
" "+deptTable+"."+colDeptName+""+
" FROM "+employeeTable+" JOIN "+deptTable+
" ON "+employeeTable+"."+colDept+" ="+deptTable+"."+colDeptID
);
InsertDepts(db);
}The method creates tables with columns, a view and a trigger. The method is invoked when the
database is created. So we create our table and specify the columns. This method is invoked when the
database does not exist on the disk, it’s executed only once on the same device the first time the application is run on the device.
Upgrading the Database
Sometimes, we want to upgrade the
database by changing the schema, add new tables or change column data types. This is done by overriding the
onUpdate(SQLiteDatabase db,int old Version,int newVerison) method:
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
db.execSQL("DROP TABLE IF EXISTS "+employeeTable);
db.execSQL("DROP TABLE IF EXISTS "+deptTable);
db.execSQL("DROP TRIGGER IF EXISTS dept_id_trigger");
db.execSQL("DROP TRIGGER IF EXISTS dept_id_trigger22");
db.execSQL("DROP TRIGGER IF EXISTS fk_empdept_deptid");
db.execSQL("DROP VIEW IF EXISTS "+viewEmps);
onCreate(db);
}This method is invoked when the version number specified in the constructor of the class changes.
When you want to append a change to your
database, you must change the version number in the constructor of the class.
So when you pass the constructor a version number of
2:
public DatabaseHelper(Context context) {
super(context, dbName, null,2);
}instead of
1:
super(context, dbName, null,2);
the application understands that you want to upgrade the
database and
onUpgrade method will be invoked. A typical implementation of this method is to drop the tables and create them again with the additional modifications.
Managing Foreign-Key Constraints
We mentioned before that
SQLite 3 by default does not support foreign key constraint, however we can force such a constraint using
TRIGGERS: we will create a trigger that ensures that when a new
Employee is inserted, his/her
Dept value is present in the original
Dept table. The SQL statement to create such a trigger would be like this:
CREATE TRIGGER fk_empdept_deptid Before INSERT ON Employees
FOR EACH ROW BEGIN
SELECT CASE WHEN ((SELECT DeptID FROM Dept WHERE DeptID =new.Dept ) IS NULL)
THEN RAISE (ABORT,'Foreign Key Violation') END;
ENDIn
onCreate method, we created this trigger like this:
db.execSQL("CREATE TRIGGER fk_empdept_deptid " +
" BEFORE INSERT "+
" ON "+employeeTable+
" FOR EACH ROW BEGIN"+
" SELECT CASE WHEN ((SELECT "+colDeptID+" FROM "+deptTable+" _
WHERE "+colDeptID+"=new."+colDept+" ) IS NULL)"+
" THEN RAISE (ABORT,'Foreign Key Violation') END;"+
" END;");Executing SQL Statements
Now let's begin executing basic SQL statements. You can execute any SQL statement
that is not a query whether it is
insert,
delete,
update or anything using
db.execSQL(String statement) method like when we did when creating the
database tables:
db.execSQL("CREATE TABLE "+deptTable+" ("+colDeptID+ " INTEGER PRIMARY KEY , "+
colDeptName+ " TEXT)");Inserting Records
We insert records to the
database using the following code for
example to insert records in the
Dept table:
SQLiteDatabase db=this.getWritableDatabase();
ContentValues cv=new ContentValues();
cv.put(colDeptID, 1);
cv.put(colDeptName, "Sales");
db.insert(deptTable, colDeptID, cv);
cv.put(colDeptID, 2);
cv.put(colDeptName, "IT");
db.insert(deptTable, colDeptID, cv);
db.close();Notice that we need to call
this.getWritableDatabase() to open the connection with the
database for
reading/writing. The
ContentValues.put has two parameters:
Column Name and the
value to be inserted. Also, it is a good practice to close the
database after executing statements.
Updating Values
To execute an
update statement, we have two ways:
- To execute
db.execSQL
- To execute
db.update method:
public int UpdateEmp(Employee emp)
{
SQLiteDatabase db=this.getWritableDatabase();
ContentValues cv=new ContentValues();
cv.put(colName, emp.getName());
cv.put(colAge, emp.getAge());
cv.put(colDept, emp.getDept());
return db.update(employeeTable, cv, colID+"=?",
new String []{String.valueOf(emp.getID())});
}The
update method has the following parameters:
String Table: The table to update a value in ContentValues cv: The content values object that has the new values String where clause: The WHERE clause to specify which record to updateString[] args: The arguments of the WHERE clause
Deleting Rows
As in
update to
execute a
delete statement, we have two ways:
- To execute
db.execSQL
- To execute
db.delete method:
public void DeleteEmp(Employee emp)
{
SQLiteDatabase db=this.getWritableDatabase();
db.delete(employeeTable,colID+"=?", new String [] {String.valueOf(emp.getID())});
db.close();
}The
delete method has the same parameters as the
update method.
Executing Queries
To execute queries, there are two methods:
- Execute
db.rawQuery method
- Execute
db.query method
To execute a raw query to retrieve all departments:
Cursor getAllDepts()
{
SQLiteDatabase db=this.getReadableDatabase();
Cursor cur=db.rawQuery("SELECT "+colDeptID+" as _id,
"+colDeptName+" from "+deptTable,new String [] {});
return cur;
}The
rawQuery method has two parameters:
String query: The select statement String[] selection args: The arguments if a WHERE clause is included in the select statement
Notes
- The result of a query is returned in
Cursor object.
- In a
select statement if the primary key column (the id column) of the table has a name other than _id, then you have to use an alias in the form SELECT [Column Name] as _id cause the Cursor object always expects that the primary key column has the name _id or it will throw an exception .
Another way to perform a query is to use a
db.query method. A query to select all employees in a certain department from a view would be like this:
public Cursor getEmpByDept(String Dept)
{
SQLiteDatabase db=this.getReadableDatabase();
String [] columns=new String[]{"_id",colName,colAge,colDeptName};
Cursor c=db.query(viewEmps, columns, colDeptName+"=?",
new String[]{Dept}, null, null, null);
return c;
}The
db.query has the following parameters:
String Table Name: The name of the table to run the query against String [ ] columns: The projection of the query, i.e., the columns to retrieveString WHERE clause: where clause, if none pass nullString [ ] selection args: The parameters of the WHERE clauseString Group by: A string specifying group by clauseString Having: A string specifying HAVING clauseString Order By by: A string Order By by clause
Managing Cursors
Result sets of queries are returned in
Cursor objects. There are some common methods that you will use with cursors:
boolean moveToNext(): moves the cursor by one record in the result set, returns false if moved past the last row in the result set. boolean moveToFirst(): moves the cursor to the first row in the result set, returns false if the result set is empty. boolean moveToPosition(int position): moves the cursor to a certain row index within the boolean result set, returns false if the position is un-reachable boolean moveToPrevious(): moves the cursor to the previous row in the result set, returns false if the cursor is past the first row. boolean moveToLast(): moves the cursor to the lase row in the result set, returns false if the result set is empty.
There are also some useful methods to check the position of a cursor:
boolean isAfterLast(),
isBeforeFirst,
isFirst,
isLast and
isNull(columnIndex). Also if you have a result set of only one row and you need to retrieve values of certain columns, you can do it like this:
public int GetDeptID(String Dept)
{
SQLiteDatabase db=this.getReadableDatabase();
Cursor c=db.query(deptTable, new String[]{colDeptID+" as _id",colDeptName},
colDeptName+"=?", new String[]{Dept}, null, null, null);
c.moveToFirst();
return c.getInt(c.getColumnIndex("_id"));
}We have
Cursor.getColumnIndex(String ColumnName) to get the index of a column. Then to get the value of a certain column, we have
Cursor.getInt(int ColumnIndex) method.
Also there are
getShort,
getString,
getDouble,
getBlob to return the value as a byte array. It's a good practice to
close() the cursor after using it.







